Rules as Code maintenance with agentic AI
Keeping your code up to date with the law used to be hard. See how Blawx is making it easy.
May 8, 2026
You guys, hold onto your butts. You're about to witness something that has never happened before in legal technology. Because it's Friday and that's how we roll.
What a Law Means Changes Even When the Text Doesn't
One of the problems in keeping laws up to date in Rules as Code is that it's not only changes to the law itself that determine how a law is interpreted, and as I keep telling people, you are never encoding the words of a law, you are always encoding an interpretation of those words.
If a court decides that the words should be interpreted differently, your code may need to change to match. But the way to find and apply judicial opinions to your interpretation of a law is more complicated than just looking at the latest version of the statutory text.
Agentic AI Is Changing Everything
A year ago, this would have been a truly hard problem. To have any hope of automating that sort of problem away, you would need to have created some system for searching relevant case law, and it would be questionable whether you could do more than just bring it to the attention of a human who could make the necessary changes, if any.
With the phenomenal advances in reasoning capabilities, and the exponential effects of giving one agent access to multiple tools, that is no longer the case.
So I did an experiment to prove a theory:
If you have an agentic AI with access over MCP to §Blawx, as well as access to a database of jurisprudence, you could just ask the agent to find relevant cases, and update the encoding accordingly.
How cool is A2AJ.ca?
The point of exposing §Blawx over remote MCP is to let §Blawx users (including agentic AI) choose for themselves how to combine it with other technologies and get the exploding capabilities that allows. So to illustrate that point, I needed a database of legal cases that was accessible over remote MCP.
Imagine my delight when the best option available is a free system exposed by York University that exposes Canadian statutes and jurisprudence! If you're aren't familiar with the Access to Algorithmic Justice site a2aj.ca, and you are a legal technology nerd, you should really check it out as an example of what good things can happen when you focus on the data.
Big props to those guys.
As an aside, I saw recently that CourtListener which focuses on statues and federal court jurisprudence in the United States is on the verge of releasing a remote MCP server that will work for anyone with a CourtListener account. Also awesome.
The Experimental Setup
My plan was to reverse engineer an example of how you might re-implement a §Blawx encoding in response to a decision of the Supreme Court of Canada. Using A2AJ over MCP, Claude found me the recent case of Piekut v. Canada (National Revenue), 2025 SCC 13 (CanLII), which reinterpreted a section of the Bankruptcy and Insolvency Act, RSC 1985, c B-3 (BIA).
I generated (using Claude, of course!) a small encoding of the interpretation that was overturned by the SCC.
The plan was to give Claude access to that encoding over the remote Blawx MCP, give it access to A2AJ the same way, and then prompt it as follows:
"I would like you to find out if there are any Supreme Court of Canada decisions issued in the last two years that would impact on the encoding in the Student Loan Discharge project on Blawx. If so, check to see if the current encoding is consistent with those decisions. If not, modify the encoding to comply with the Supreme Court decision. "
The Piekut Case
In Piekut, a student who was seeking the discharge of her student loans under bankrupts was arguing the definition of s 178(1)(g)(ii) of the BIA, which reads as follows:
178 Debts not released by order of discharge
(1) An order of discharge does not release the bankrupt from
(g) any debt or obligation in respect of a loan made under
the Canada Student Loans Act, the Canada Student
Financial Assistance Act or any enactment of a province
that provides for loans or guarantees of loans to students
where the date of bankruptcy of the bankrupt occurred
(ii) within seven years after the date on which the
bankrupt ceased to be a full- or part-time student;The disagreement was over whether the "seven years" in (ii) was calculated from the end of each stint of full-time-student-being, or if re-enrolling as a full-time student meant that it constituted a single period of full-time studentship. Piekup had entered into bankruptcy bewteen two stints of studying, and wanted the older stints discharged. The government disagreed, and argued that the 7 years should run from the last period of studies.
The Supreme Court sided with the government, deciding that the seven year period should start from only the last period of studies.
What I was hoping to see from the agent is that it can
- find the case,
- detect the inconsistency,
- confirm the inconsistency by running the code,
- encode a fix, and
- run the code again to confirm the fix.
The Result
The test was run on Claude Desktop using Opus 4.7 Adaptive. The agent ran for about 20m to finish, and the only human inputs were permission to use tools, and permission to continue despite how many tools it was using.
What did Claude do?
- find the case,
- detect the inconsistency,
- confirm the inconsistency by running the code,
- encode a fix, and
- run the code again to confirm the fix.
This was on the first attempt.
At this point, it's probably best that you don't believe me.
If you would like to look at the actual chat in which it happened, it's available here.
If you would like to watch a 16x sped up video recording (about 100s) of Claude doing it's thing, here you go:
If you would like to import the encodings using your own §Blawx account:
If you would like to see the only part of the encoding that changed, it went from this:
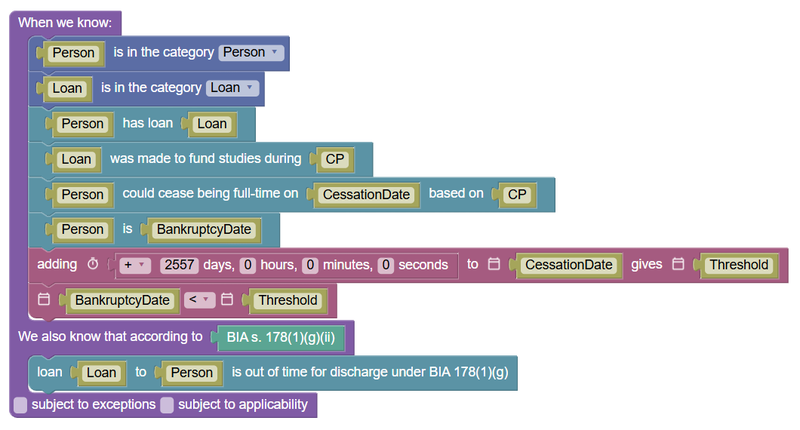
to this:
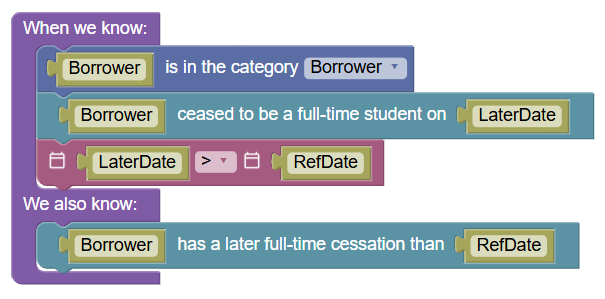
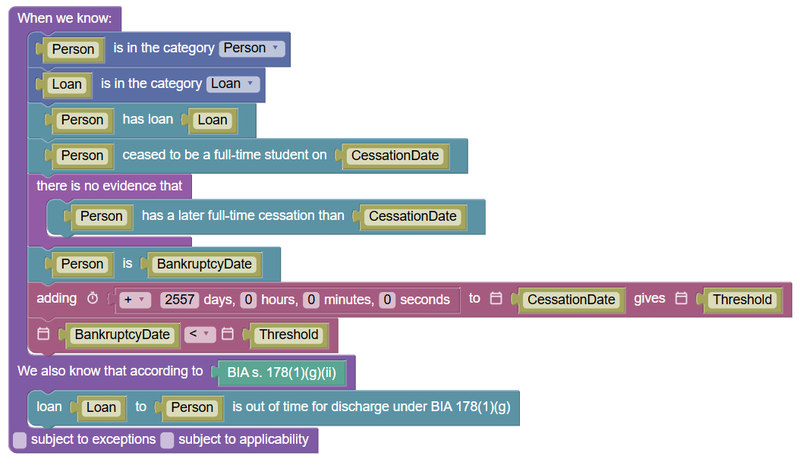
Were there Hiccups?
Yes, two. One was caused by errors in the Blawx MCP server's documentation, which Claude quickly overcame by looking for examples to follow.
The other did not affect the correctness of the encoding, the MCP server made the issue almost completely invisible to the agent, and the error was there before Claude started on its task. So it sort of failed to fix a problem it couldn't see. See how the text on one of the relationship blocks in both the before and after encodings says "[Person] is [BankruptcyDate]"? It should have read "the date of bankruptcy of [Person] is [BankruptcyDate]".
I don't think it's a hiccup exactly, but the MCP server is currently very token expensive with its output, so the process can be made more affordable. And it's possible there are things that can be done to make it faster, too.
But did it correctly encode the re-interpretation of the section of code consistently with the SCC decision in Piekut? Yes it did. Alone.
Wait... How Big a Deal Is This?
Right. Right. I keep forgetting, sorry. No one but me obsesses over this stuff.
§Blawx is at the absolute cutting edge, here.
Let me point to a couple of scientific papers that were recently published on the topic of getting LLMs to help generate encodings of laws in logic-based rules as code languages, and then compare and contrast the experiments I've been doing this month.
Legal2LogicICL (April 2026)
"Legal2LogicICL: Improving Generalization in Transforming Legal Cases to Logical Formulas via Diverse Few-Shot Learning" (Jieying Xue, Phuong Minh Nguyen, Ha Thanh Nguyen, May Myo Zin, Ken Satoh; arXiv:2604.11699, April 2026) Arxiv
This paper demonstrates techniques in using LLMs to generate encoded fact scenarios in a language called Proleg based on natural language descriptions of the fact scenarios.
LLMs Writing DDL (Dec 2025)
"Toward Robust Legal Text Formalization into Defeasible Deontic Logic using LLMs" (Elias Horner, Cristinel Mateis, Guido Governatori, Agata Ciabattoni; arXiv:2506.08899, June 2025; v3 Dec 2025) Arxiv
This paper illustrates techniques for improving, according to a specific rubric, the encodings generated by LLMs in the DDL language of rules expressed in Australian telecommunications statutes.
How §Blawx Compares and Contrasts
In comparison, people who appreciate the potential of logic programming techniques in Rules as Code are all actively looking for ways to make generating and maintaining the code faster. So my experiments with §Blawx in the last month are aimed at the exact same problem that computational law researchers around the world are actively addressing.
In contrast, what I'm trying to do is harder.
The Legal2LogicICL paper is testing only the ability to generate accurate fact descriptions in Proleg from natural language descriptions of those facts.
Similarly, the DDL paper is targeting a language that does not have complex terms. They are only encoding rules, and their rubric for judging the results does not address whether the encodings generate correct answers.
Both papers are using prompting approaches, sometimes with multiple steps.
With §Blawx, I am using an agentic approach, not prompting, to encoding rules, judicial opinions, facts, questions, and vocabulary, all needing to work with each other, in an answer set programming language that is being expressed not in prolog-like text, but as a semantically correct, vocabulary-compliant encoding that is also valid §Blawx code, that is also valid Blockly code, that is also valid JSON, all of which is necessary to generate a user interface that is more friendly than text for non-programmers.
Also in contrast, their experiments are bigger, more scientific, and peer reviewed. Mine are toy examples and anecdotes. Because this is not my job, it's my hobby.
And let me be clear. I'm not dunking on the authors of those papers. I've been learning from their work for about a decade, I have met many of the authors in person, and I genuinely admire them and their work. I'm only able to do what I'm doing because I learned from what they were doing decades ago.
And the difference in scope of what they are trying is not due to any disagreement on what's important, or what's possible. They have an obligation to prove things with a formality that I'm utterly free of. I can build something that works, and I don't know why, and there's no one asking me about how often my papers got published in peer reviewed journals, or how often they were cited. No one is expecting me to do any admin work, support graduate researchers, or teach classes.
The point is that I'm aware of the prior art. And with that awareness, I'm confident what §Blawx allows you to do is world-first cutting edge stuff.
In a world where lawyers are trying to figure out what the future of legal practice will look like if AI keeps automating things that they used to get paid for, new legal tasks with new legal tools that are built around the strengths and weaknesses of both humans and AI are kind of a big deal.
You're welcome, future. 😅
What's Next?
I genuinely don't know. Maybe improve token efficiency in the MCP server, maybe more formal verification experiments, maybe improved workflows for testing and validation, maybe some UX and collaboration improvements, maybe improved documentation and training resources... there are a lot of options. Stay tuned.